|
6. Search and Retrieval |
twinIsles.dev >> Photography on the Web
| 6.1 The Importance and Role of an Effective Search and Retrieval Mechanism A collection of resources of any kind is only useful if it contains the resource(s) an enquirer requires, and the enquirer is able to locate those resource(s). The efficient location of resources is dependent upon the employment of an effective system of creating and utilising metadata about the resources. Metadata is data about data, or in the case of images data about images. The issue of search and retrieval in the proposed web site (or any non-trivial site) is essentially a microcosm of the problem faced by users of, and contributors to, the World Wide Web in its entirety. The role of the search-retrieval mechanism may be illustrated graphically.
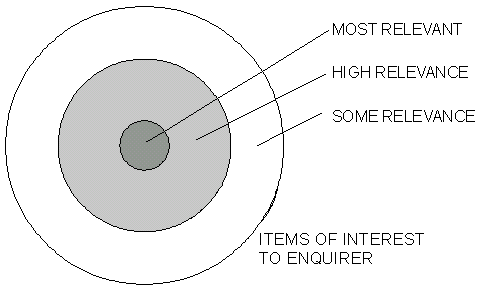
Fig 6.1 Searching a Collection The aim of the search-retrieval mechanism is to minimise the shaded areas in Fig 6.1; i.e. to maximise both the proportion of relevant items returned and the proportion of items returned which are relevant. These two measures were termed recall and precision by Cleverdon, whose work is described by Lesk [58]. It is likely that those items of interest will have varying degrees of relevance to the enquirer, which should be reflected by the search-retrieval mechanism. Relevance is normally indicated by the order in which results are shown, with the most relevant items appearing first. Kobayashi and Takeda [56] describe a three way trade-off "between speed of information retrieval, precision and recall". Of particular importance to web users is "the number of valuable sites... listed in the first page of retrieved results". Criticism of retrieval times was also found in my survey of image users (Appendix B). This seeming impatience is almost paradoxical given that the web provides desktop access to enormous quantities of valuable information the acquisition of which would otherwise demanded visit to numerous reference libraries. However, technology will inevitably deliver ever faster infrastructure and domestic broadband access as the norm. 6.2 The Indexing of Textual Items 6.3 Problems Associated with the Indexing of Non-textual Materials The Introduction to the Library of Congress Thesaurus for Graphic Materials I [59] states that "By their very nature, most pictures are 'of' something", but "In addition, pictorial works are sometimes 'about' something; that is, there is an underlying intent or theme expressed in addition to the concrete elements depicted." For example a photograph may be of a long line of cars outside a petrol station. The same picture may be about protests over fuel tax rises. The aforementioned introduction goes on to say "Subject cataloging must take into account both of these aspects if it is to satisfy as many search queries as possible." 6.4 The Vocabulary Mismatch Problem 6.5 Content Based Image Retrieval One practical application of CBIR currently available is that of filtering pornography. British-based company First 4 Internet [37] launched its Image Composition Analysis software version 1.8.1 in May 2001 "to protect PC users from pornographic images". AltaVista's Image Search feature [2] makes use of content based retrieval to find images that are "visually similar" to a selected one where "Similarity is based on visual characteristics such as dominant colors, shapes and textures". 6.6 Vocabularies 6.6.1 Thesauri
The J. Paul Getty Trust has made a number of vocabulary databases available online; the Art and Architecture Thesaurus (AAT) [49], the Union List of Artist Names (ULAN) [52] and the Getty Thesaurus of Geographic Names (TGN) [50]. The Library of Congress Thesaurus for Graphic Materials I [60] is also available on the Web. Differences in descriptions are likely to occur between indexer and searcher, between different indexers and even by the same indexer at different times. The latter two cases would result in an inconsistent catalogue. This problem underlines the need for a thesaurus to be consulted in both the cataloguing and indexing processes. Millstead [66] describes how thesauri were originally designed to facilitate consistent indexing of documents, but predicted (in 1998) they "may soon be used more at retrieval than at input". Millstead recommends that the thesaurus should be invisible to the user unless they choose to examine it, she writes "we need to design our interfaces so that users need not interact directly with the thesaurus to any greater extent than they wish or need to".
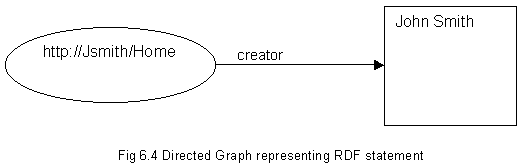
Thesauri are consulted by search algorithms to ensure the broadest range of relevant resources is returned even where the terminology used in the search criteria differs to that found in the resource description. Thesauri can also be used to suggest alternative search terms. Thesauri are often specific to the collection they describe. However the increasing use of the web to both publish and search across a diverse range of resources has created the need for a mechanism to effectively interrogate different sets of metadata. Doerr [22] considers this problem in detail and calls for a common methodology for thesaurus construction. 6.7 Types of Metadata One widely recognised standard for metadata categorization is the Dublin Core from the Dublin Core Metadata Initiative [92]. The Dublin Core consists of fifteen elements "likely to be useful across a broad range of vertical industries and disciplines of study". The elements are Title, Creator, Subject, Description, Publisher, Contributor, Date, Type, Format, Identifier, Source, Language, Relation, Coverage, Rights. The World Wide Web Consortium (W3C) has developed Resource Description Framework (RDF) [57] in response to the problems in accurate information retrieval on the web. RDF is a means of making web resources machine understandable and is used describe resources and their properties. A resource is anything identifiable by a URI (Uniform Resource Identifier). Resources, properties and their values (also referred to as subject, predicate and object respectively) are represented by RDF statements. E.g. in the sentence John Smith is the creator of resource http://Jsmith/Home, creator is a property of the resource, John Smith is its value. RDF statements can be represented by directed graphs (see Fig 6.4). Properties and their values may also be described by URIs.
RDF uses XML (see 5.5) as its language of implementation. The W3C Specification document provides examples of web pages described with RDF according to the Dublin Core elements. Kobayashi and Takeda [56] describe how the usefulness of metadata on the web is often diluted by its manipulation to improve search engine result ranking. Such techniques include attaching popular (but irrelevant) keywords and "spamming, i.e., excessive, repeated use of keywords or 'hidden' text". One means of hiding text is to display it in the same colour as the background, thus rendering it invisible to the user, but not to automatic indexing software. 6.8 Review and Refinement 6.9 The Human Factor Two kinds of expertise may be identified; firstly the cataloguer's knowledge of the subject matter, and secondly the system designer's expertise in providing a framework for the efficient storage of metadata and the accurate location and retrieval of resources in response to requests (this would encompass skills such as database design, normalization and query formulation using, for example, SQL). It cannot be assumed that those most suited to the cataloguing of resources possess I.T. skills, nor that those most capable of designing the search mechanism infrastructure have detailed knowledge of the subject matter, therefore close communication between these two skill sets is essential during the design phase. Ideally once the structure of the search mechanism is determined the process of cataloguing should, as far as possible, benefit from automation. The cataloguer is presented with a form to be completed for each item being added to the collection. In addition to serving as an aide-mémoire to the completeness of each record the form may also ensure consistency by, for example, offering list boxes of fixed choices; although in this case it should be sufficiently flexible to allow the cataloguer to define new categories where those offered are inadequate. The underlying software would automatically update the database of metadata ensuring integrity is maintained. The cataloguer would have no need to be aware of the actual database structure. It seems likely that the problem of information overload (see
2.5.4) associated with the web will bring about more intelligent search
tools and the wider availability of increasingly more intelligent agents
(see 2.9). For example where the initial search
criteria is vague or ambiguous the software may respond with further questions
(in natural English) in order to elicit a more precise description of
requirements. |
twinIsles.dev >> Photography on the Web