|
9. Search and Retrieval Mechanism |
twinIsles.dev >> Photography on the Web
|
The database structure and search mechanism are described. 9.1 Database Design
The database structure is of the form:
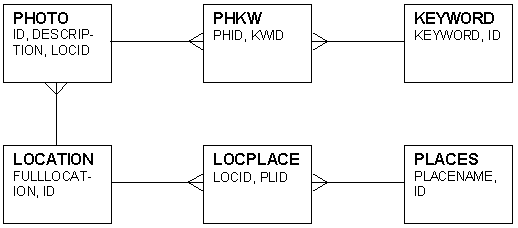
Fig 9.1 Database Structure
Fig 9.2 Database Tables and Fields N.B. fullLocation refers to a full location, e.g. Burnley, Lancashire, England, Britain, UK; placeName is a single term e.g. New York, Asia, Brighton. The number of categories of metadata held for each image is currently considerably less than that recommended by standards such as the Dublin Core [92]. This is deliberately so and reflects the fact that many of the Dublin Core categories (e.g. publisher, language etc.) have no meaning or relevance to the image collection at the present time. The structure and implementation of the database mean that additional categories could be added relatively easily should the need arise; e.g. a creator field may become necessary if twinIsles accepts work from other photographers, a date field may be added in response to user feedback. Keywords consist of single words. The facility to search for phrases (fixed groups of words) as commonly found on web search engines has not been included in the prototype. Instead, the ranking algorithm (described below) has been adopted as a means of providing best match first results without the need for phrase matching. However, phrase matching has been identified as a possible future enhancement to the image retrieval mechanism. 9.2 Collections Where all images in a collection share the same description e.g. the
Sumo collection they do not appear individually in the database (see note
below). However where the collection consists of a diverse range of images,
e.g. Reflections, Shadows and Light, each image remains in the database
in its own right. The implications of this policy are that a search for
Sumo returns a single thumbnail linking to the Sumo collection, a search
for Japan returns the Sumo collection along with other images, a search
for reflections returns the Reflections Shadows and Light collection along
with other images matching the search (some of which are also contained
within the collection) and a search for windows returns some of the images
from the Reflections Shadows and Light collection but not the collection
itself (since the search criteria is not sufficiently strongly related
to that collection's description). Note: in fact every image is catalogued individually in the database, however those images which should only appear as part of a collection are prevented from being returned in search results by not being referenced by other tables. 9.3 Database Creation and Population The description and additional keyword fields were exported to a text file and individual keywords were extracted using a purpose-written Java program. (Java was used as a procedural language and was chosen merely for its ready availability). The resulting sequential list of keywords was imported back into the spreadsheet where it was edited manually to remove words such as "a" and "the". Each keyword was then given an identifier (an integer). During this process synonyms were identified, which were given identical identifiers. Thus, someone searching for marriage would receive results featuring the word wedding as a keyword. In keeping with the convention found in other thesauri plural forms were added to singular noun keywords. The keywords and identifiers were saved as a text file. Another Java program was used to identify which keywords in the keywords file appeared within each photograph's description and additional keywords. A further text file was created consisting of a comma delimited list of photograph identifiers and keyword identifiers. The location of each item was initially entered as a single place name at the most specific level, e.g. Brighton. The individual place names used were identified and a fully qualified location (full location) was created for each, e.g. the full location for Brighton is Brighton, Sussex, England, Britain, UK. Thus, Brighton images would be returned to a user searching for Sussex, England, Britain, UK, or indeed, Brighton. Each full location was given a unique identifier and a text file created holding the full locations and their corresponding identifiers. Each unique place name used in the fully qualified locations was extracted with a Java program and given an identifier. Multi-word places such as Hong Kong, Covent Garden are indexed both on their full name and also on the (significant) individual components of that name. The place names and identifiers were stored in a text file. Another text file was created, also with a Java program, associating place name identifiers with location identifiers. Finally a text file was created containing the details of each item, namely its identifier, textual description and identifier of its location (which may be null). A database, consisting of six tables matching the structure described above, was created in Microsoft Access. The data was then imported into Access from the text files created from the above description. Microsoft Access was selected for the following reasons:
9.4 The Search
In keeping with many web-based search tools the user is offered a choice of quick and advanced search modes. The quick search is presented by default and consists of a single text box. The advanced search provides two text boxes; one for subject, the other for location. In order to keep the number of images per page to a manageable number a maximum of 30 images is displayed per page. Where more images exist the user is offered a "more" link, which passes the page number and search string back to the same ASP page via the query string. 9.4.1 The Quick Search SELECT photo.ID, description,
fullLocation As only a single search string is used the terms contained must be sought in both keywords and place names. The queries for keyword and place name are joined with UNION ALL and the final query terminated with ORDER BY photo.ID. Since UNION ALL returns duplicate rows the results provide a rudimentary ranking of closeness of match, i.e. the more search term matchings the more times an item was returned. The results are then collated using VBScript with a score being assigned to each distinct item returned equal to the number of times it was returned. VBScript is then used to display the results showing the most relevant items (in terms of numbers of matchings) first. 9.4.2 The Advanced Search Items are ranked according to the number of matches between search terms and their description. In the case of location only being entered the following query is created: Items are ranked according to the number of matches between search terms and their location. In the case of both subject and location being entered the following
query is created: Items are ranked according to the number of matches between subject search
terms and their description. Only items which match at least one location
term are returned. Consideration was given to supporting Boolean operators such as AND and OR in the search but this facility is not included in the prototype for two reasons. Firstly these operators require some skill on the part of the user if ambiguity is not to arise, e.g. does cat AND dog OR mouse mean (cat AND dog) OR (cat AND mouse), or does it mean (cat AND dog) OR mouse? Secondly, the ranking algorithm described above provides the advantages of AND and OR searching with ANDed results being returned first, followed by the ORed results. User feedback and search logs will be carefully monitored and the policy for Boolean searching will be reviewed if appropriate. 9.4.3 Proposed Modifications The simplest approach would be to return only the first n results, notifying the user and directing them to the Advanced Search. However, a more satisfactory solution would be to identify keywords (and/or placenames) with large numbers of matches and to amend the SQL query so that these terms are ANDed with the other term(s). E.g. in the case of a search for "festivals Japan", the term Japan would produce many matches. As the search mechanism stands each of these would be returned along with every match for festivals (with images matching both terms being shown first). The proposed modification would mean that only images matching Japan AND festivals would be returned. This would most likely be in accordance with the searcher's intentions. At present results arising from multiple search terms are ranked according to the number of matches between items and search criteria, however no ranking is applied to results from a single search term. It may be beneficial to rank such results based upon the number of times the thumbnails have previously been clicked, effectively displaying the most popular items first. Adding new images to the collection is currently somewhat complex as it involves a similar process to that described above for the initial database population. This would be unsuitable for a cataloguer who did not have detailed knowledge of the database structure and considerable I.T. skills, neither of which should be required of a cataloguer. Therefore an automated system of cataloguing should be developed in which a form is completed for each image to be added. The system should refer to a thesaurus describing the various relationships between its terms. Appendix E suggests a model for such a system. Often users make keyboard or spelling errors when entering data into a computer. A possible enhancement to both search and cataloguing features would be a spell-checker that would not only identify misspelt words but also suggest valid alternatives. 9.5 The Category Index The index includes the collections described in 9.2 above. Other categories are displayed dynamically in response to the database being queried. This has the advantage that new images are automatically included in the appropriate categories. |
twinIsles.dev >> Photography on the Web
Next Other Considerations